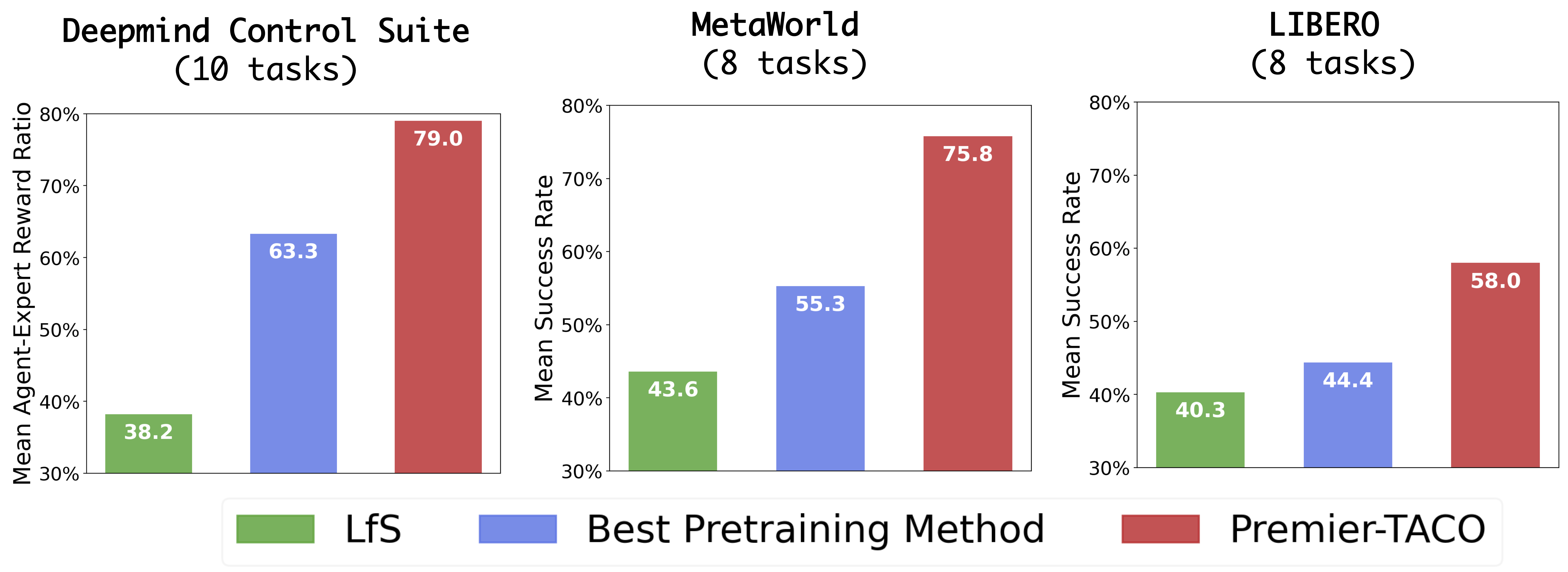
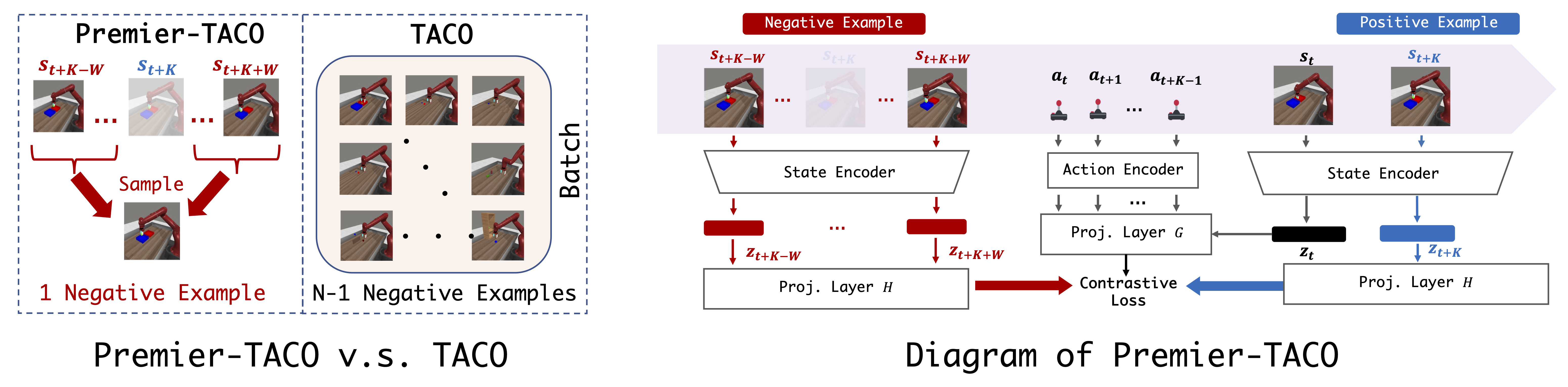
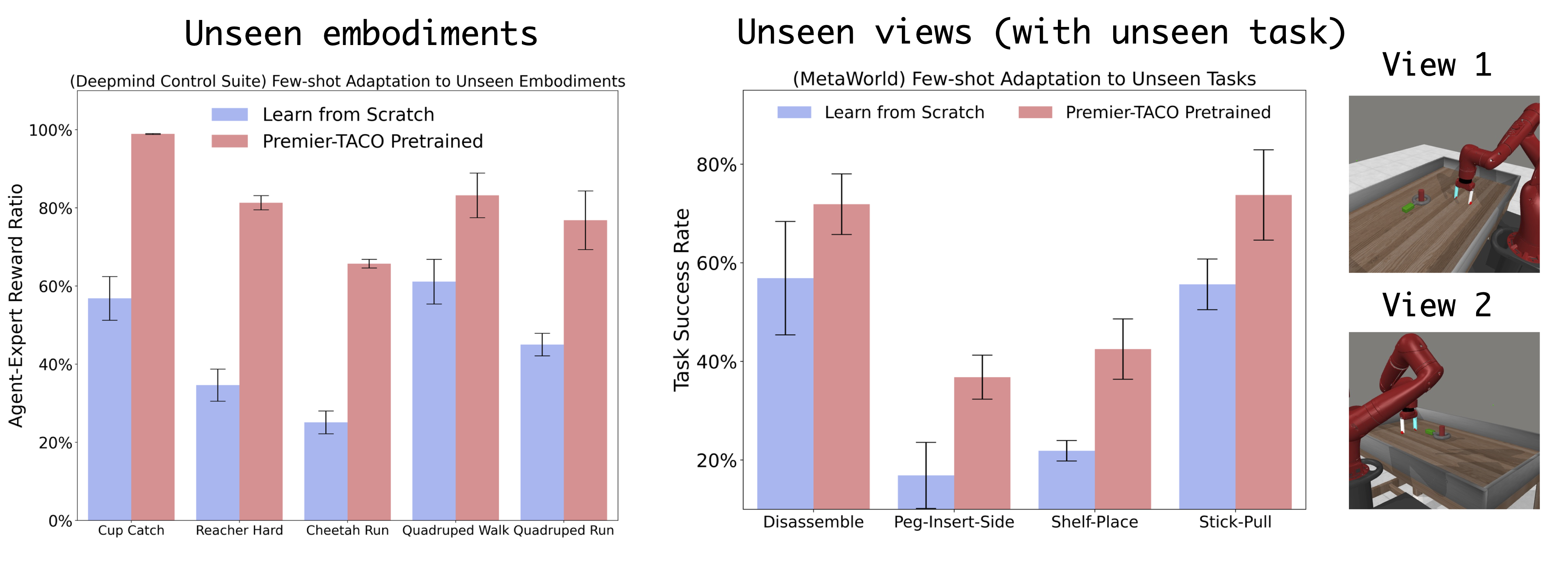
We present Premier-TACO, a multitask feature representation learning approach designed to improve few-shot policy learning efficiency in sequential decision-making tasks. Premier-TACO leverages a subset of multitask offline datasets for pretraining a general feature representation, which captures critical environmental dynamics and is fine-tuned using minimal expert demonstrations. It advances the temporal action con- trastive learning (TACO) objective, known for state-of-the-art results in visual control tasks, by incorporating a novel negative example sampling strategy. This strategy is crucial in significantly boosting TACO’s computational efficiency, making large-scale multitask offline pretraining feasible. Our extensive empirical evaluation in a diverse set of continuous control benchmarks including Deepmind Control Suite, MetaWorld, and LIBERO demonstrate Premier-TACO’s effectiveness in pretraining visual representations, significantly enhancing few-shot imitation learning of novel tasks.